Artikel ini merupakan adaptasi dari paper berikut.
Pada artikel kali ini penulis akan menjabarkan proses data mining dari salah satu paper yang penulis buat menggunakan Orange Data Mining. Paper ini merupakan submisi penulis pada lomba GEMASTIK XIII dan sayangnya tidak lolos dan diikutsertakan kembali pada lomba CODIG Mercubuana 3.0 dan berhasil masuk sebagai finalis.
Metode Penelitian
Pada penelitian ini penulis mengambil studi kasus untuk melakukan clustering potensi provinsi di Indonesia untuk digunakan sebagai daerah pertanian. Pada kasus ini komoditas yang dipilih adalah bawang putih karena bawang putih selain menjadi salah satu rempah yang menjadi bahan pokok di masakan lokal Indonesia, datanya juga saat itu mudah didapatkan oleh penulis. Setelah memilih apa komoditas yang akan dijadikan dasar pemodelan, tahap selanjutnya adalah mengidentifikasi apa saja variabel yang berkontribusi terhadap pertumbuhan bawang putih.
graph LR
A[Bawang Putih] --> B[Variabel yang Berkontribusi]
B -->C[Iklim, kering]
B -->D[Suhu, 15-20 *C]
B -->E[Curah Hujan, 110-200mm/bulan]
B -->F[Ketinggian, 700-1000 mdpl]
B -->G[pH Tanah, 6-7.5]
Berdasarkan variabel-variabel di atas, penulis mulai mencari sumber data dari beberapa sumber seperti BMKG dan sumber data terbuka di GitHub, Kaggle, dan Our World in Data. Pada akhirnya penulis berhasil mengumpulkan beberapa data yang memiliki relasi kuat dengan faktor-faktor yang sebelumnya sudah ditentukan.
Kamu bisa unduh dataset yang sudah penulis kurasi dari berbagai sumber pada tautan di bawah ini.
| Atribut | Tipe Data | Keterangan |
|---|---|---|
| latitude | float | Koordinat pada garis bujur bumi |
| longitude | float | Koordinat pada garis lintang bumi |
| volume_hujan | float | Volume hujan dalam kurun waktu satu tahun |
| jumlah_hari_hujan | integer | Berapa banyak hari turun hujan dalam kurun waktu satu tahun |
| suhu_avg | float | Rata-rata suhu udara dalam kurun waktu satu tahun |
| tekanan_udara | float | Rata-rata tekanan udara dalam kurun waktu satu tahun |
| penyinaran_matahari | float | Rata-rata luas penyinaran matahari |
Seperti yang terdapat pada tabel di atas, terdapat beberapa variabel yang tidak sama persis dengan faktor-faktor yang ada pada diagram tetapi dapat mengimplikasikan faktor-faktor tersebut misalnya ketinggian berkorelasi dengan tekanan udara, semakin tinggi suatu daerah maka tekanan udara akan semakin rendah dan begitu pula sebaliknya. Berdasarkan informasi ini informasi kualitatif (dataran tinggi, dataran rendah) bisa diturunkan dari informasi kuantitatif (tekanan udara).
Pemodelan menggunakan Clustering
Seperti yang sudah dijelaskan sebelumnya bahwa target dari penelitian ini adalah membuat cluster mana saja daerah yang cocok untuk ditanami bawang putih berdasarkan faktor-faktor yang sudah ditentukan. Pada penelitian ini akan digunakan metode hierarchical clustering menggunakan average linkage untuk menentukan cluster-cluster daerah. Setelah didapatkan cluster-cluster daerah, tahap selanjutnya adalah menggabungkan data cluster dengan dataset asli untuk membuat visualisasi berupa diagram kotak garis untuk menginterpretasi karakteristik setiap atribut pada cluster tersebut dan memvisualisasikan daerah cluster pada peta.
Buka aplikasi Orange Data Mining.
Tambahkan widget Data > File. Setelah itu pilih file CSV yang sudah kamu unduh dari tautan di atas. Pastikan semua kolom dan role sama seperti di bawah ini.
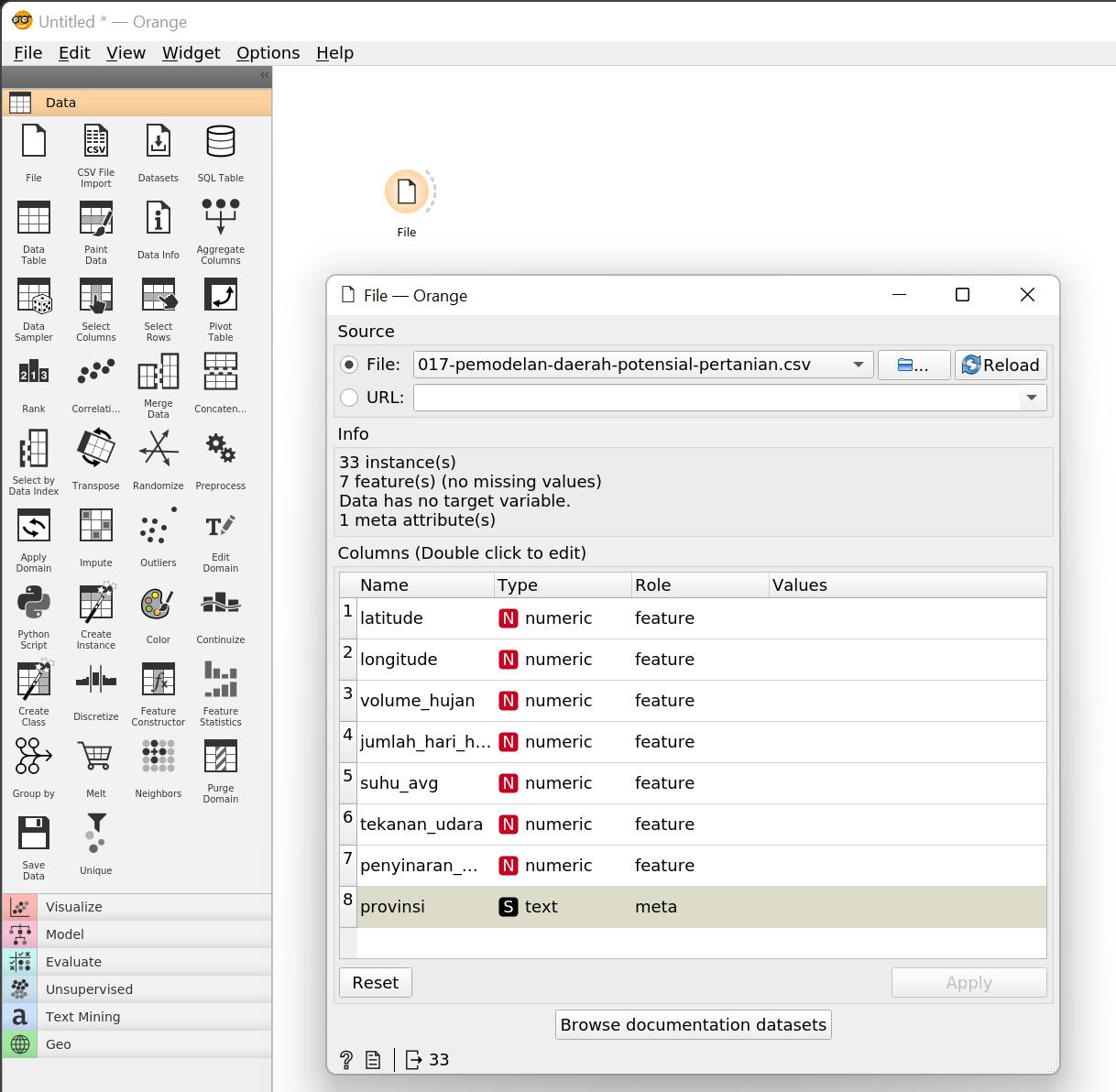
Setelah kamu menambahkan widget File, kamu bisa menggunakan widget Data Table untuk melihat isi dataset.
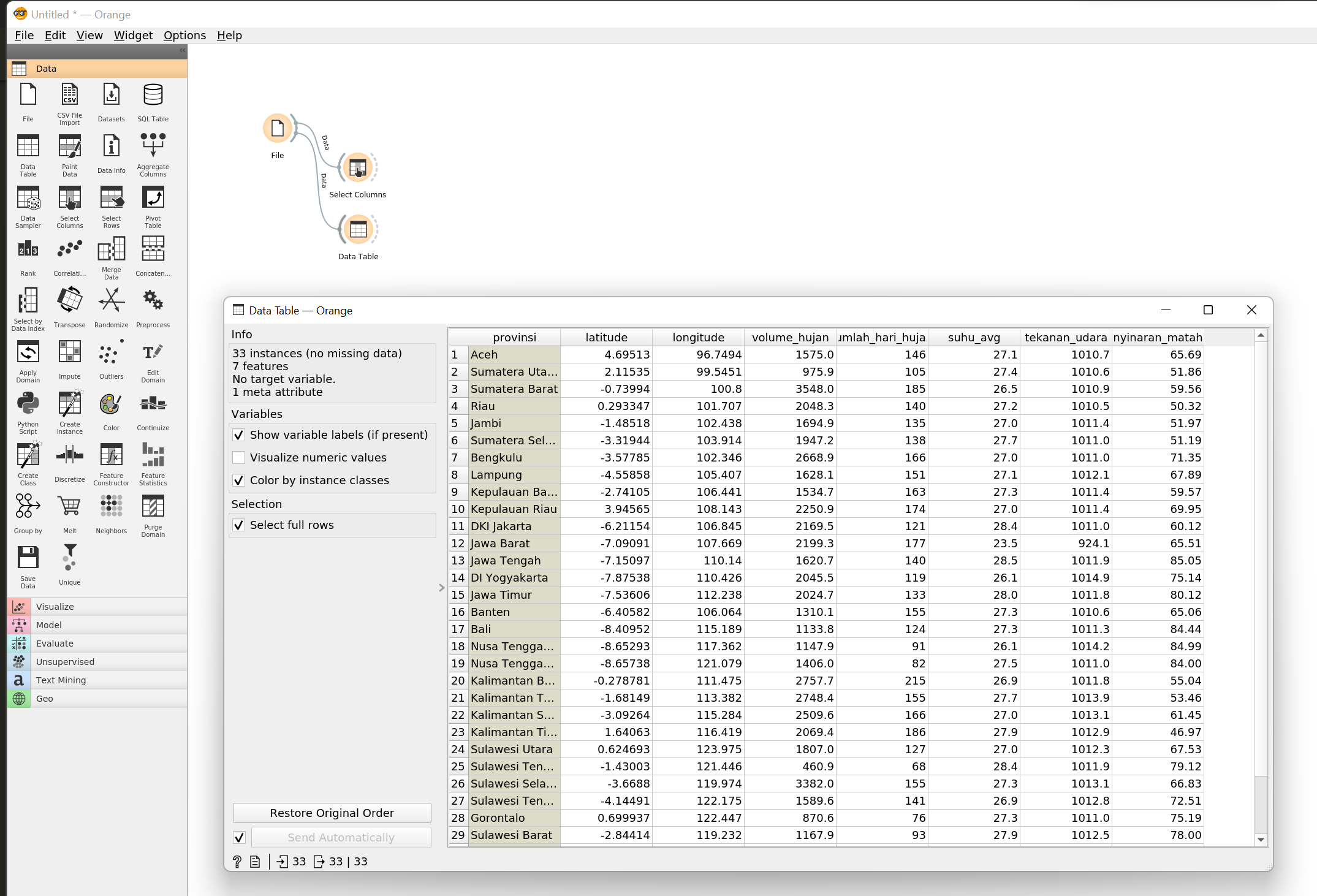
Setelah kamu berhasil memuat data, tahap selanjutnya adalah memilih atribut yang akan digunakan untuk melakukan
clustering. Ingat bahwa pada data ini terdapat atribut latitude dan longitude yang merupakan koordinat provinsi
pada peta dan pada hakikatnya koordinat ini tidak termasuk pada faktor yang berkontribusi pada pertumbuhan bawang putih,
maka dari itu kolom tersebut perlu dibuang terlebih dahulu.
Tambahkan widget Select Columns kemudian geser atribut latitude dan longitude dari daftar Features ke daftar
Ignored.
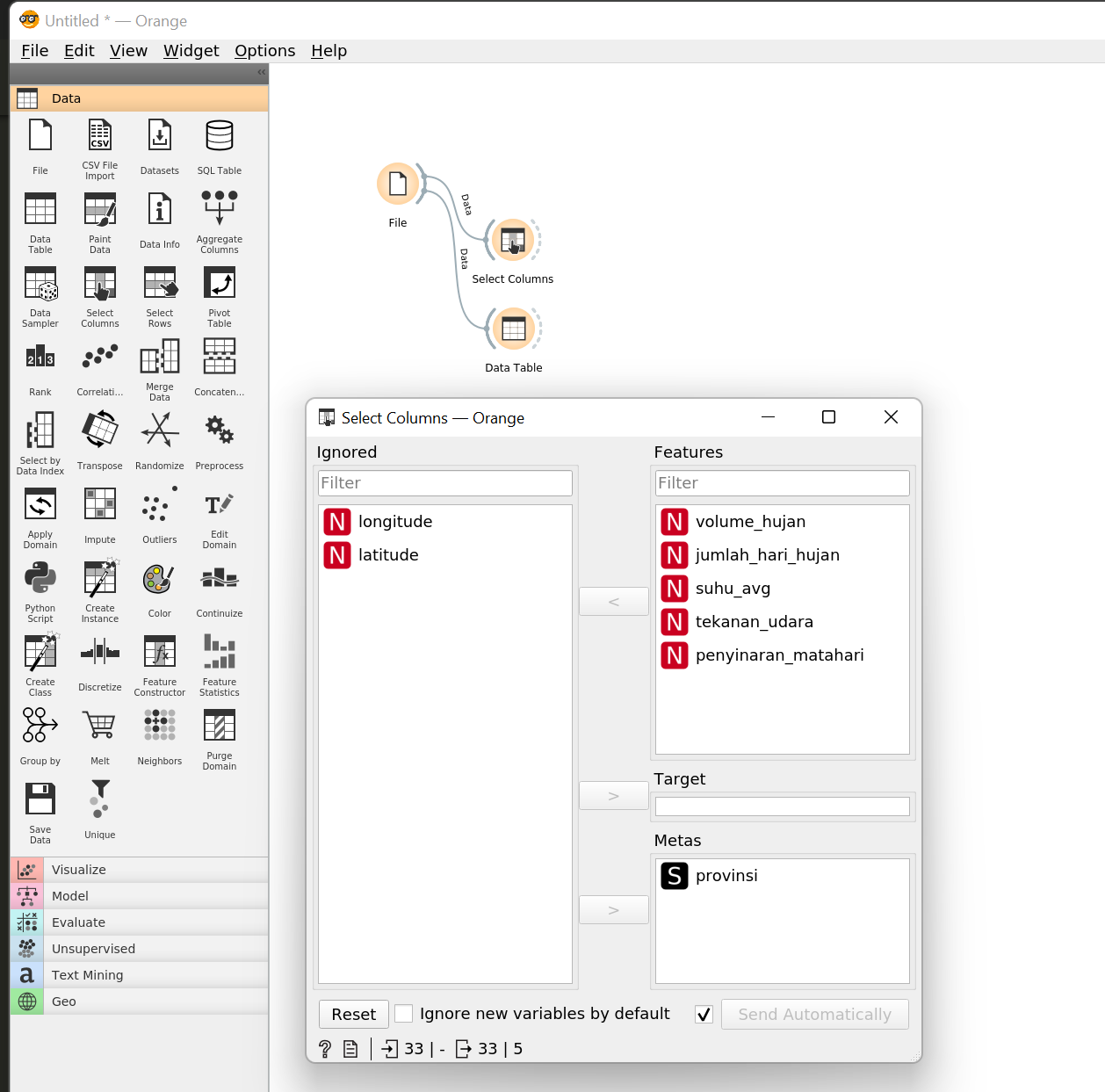
Setelah kamu memilih kolom yang akan digunakan pada proses clustering, tahap selanjutnya adalah menambahkan widget Unsupervised > Distances dan Hierarchical Clustering.
- Pada widget Distances, ubah Distances between menjadi Rows dan Distance Metric menjadi Cosine.
- Pada widget Hierarchical Clustering, ubah Linkage menjadi Average dan kamu juga bisa menambahkan anotasi dengan memilih atribut provinsi pada bagian Annotations. Pastikan Top N adalah 5 yang artinya kita akan memilih lima hierarki teratas sebagai cluster.
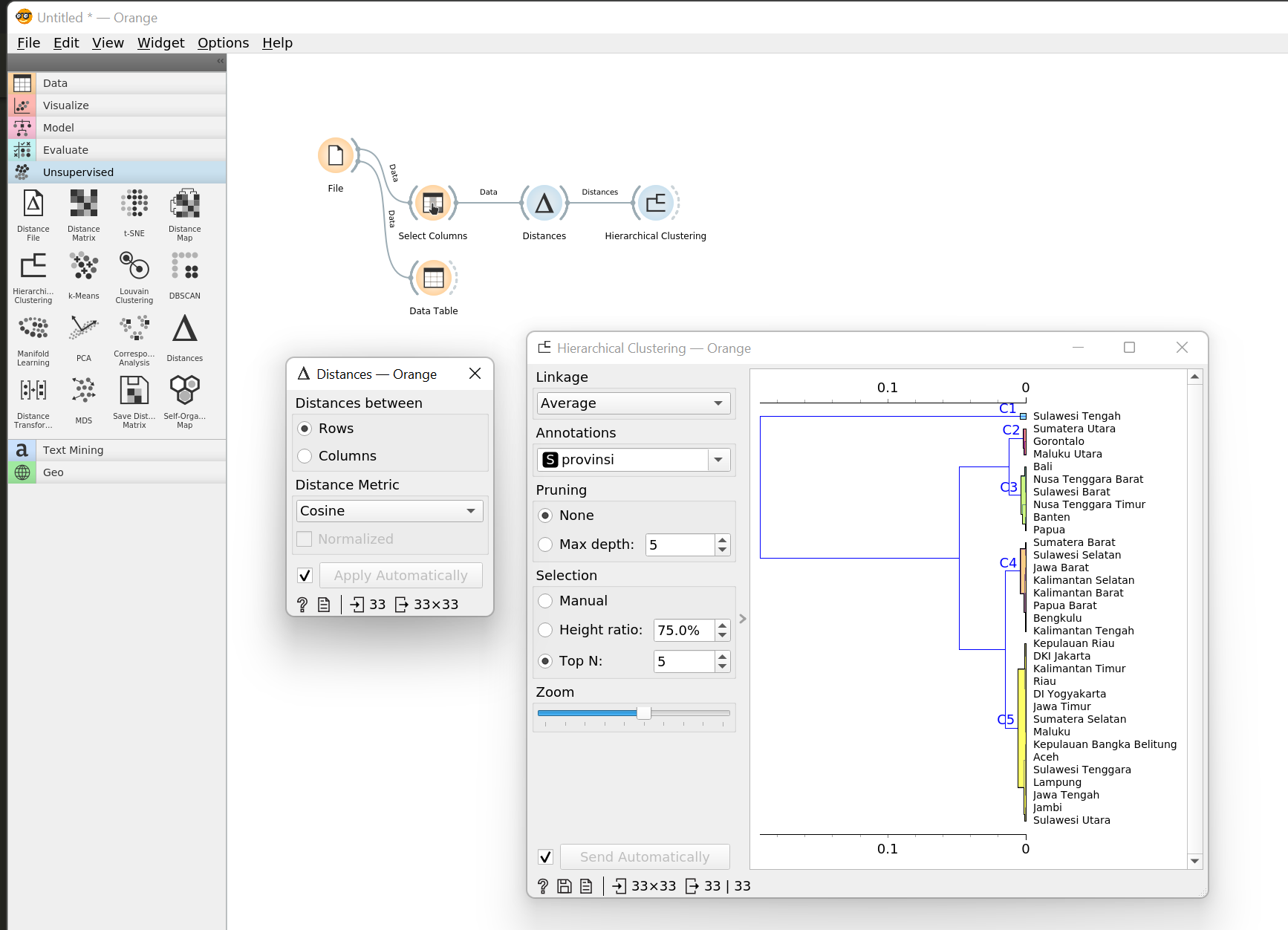
Sampai di sini kita sudah memiliki cluster untuk tiap-tiap provinsi di Indonesia. Berdasarkan dendogram di atas (struktur hierarki di atas disebut dendogram) bisa dilihat terdapat lima cluster dan masing-masing nama provinsi yang masuk ke dalam cluster tersebut.
Sebelum melanjutkan proses untuk menginterpretasi karakteristik tiap-tiap cluster, kita akan melakukan visualisasi silhouette scores untuk kelima cluster yang sudah dibuat. Metode evaluasi menggunakan silhouette score ini merupakan salah satu metode evaluasi cluster yang paling mudah digunakan. Secara umum silhouette score menunjukkan jarak rata-rata antara titik data pada cluster dibandingkan dengan jarak dengan cluster lain, sehingga semakin besar silhouette score berarti titik data berada jauh dari cluster lainnya dan dapat disimpulkan bahwa titik data tersebut sudah masuk ke dalam cluster yang tepat. Tentu interpretasi ini bukan alasan terbaik, kamu bisa coba pelajari lagi mengenai silhouette score dan juga metrik-metrik lain untuk mengevaluasi cluster seperti Davies-Bouldin Index.
Untuk membuat plot silhouette score, tambahkan widget Visualize > Silhouette Plot, kemudian hubungkan dengan output dari Hierarchical Clustering.
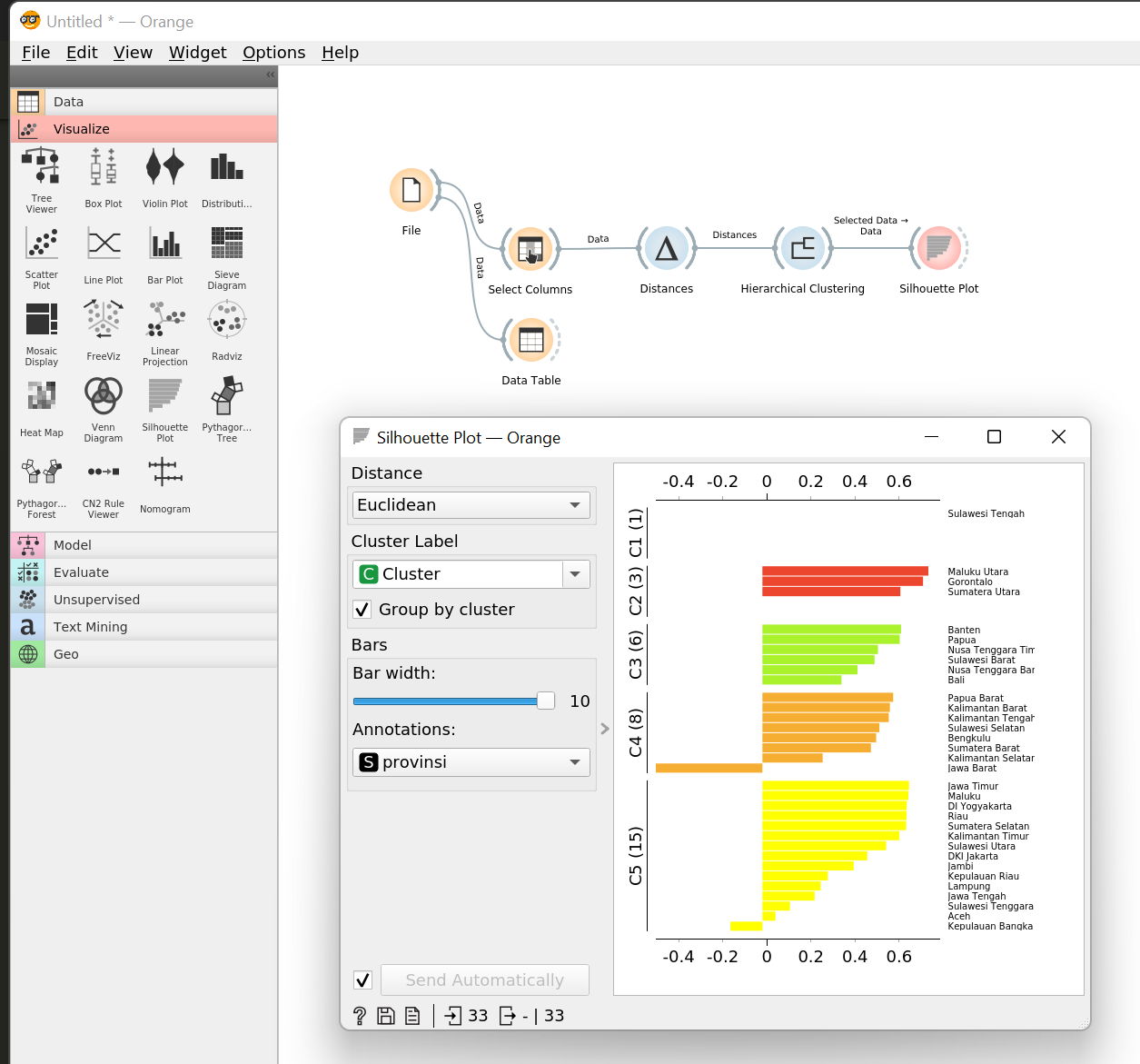
Dapat dilihat pada plot di atas ada beberapa sampel data yang memiliki nilai silhouette score yang negatif, artinya titik data tersebut memiliki jarak yang lebih dekat dengan cluster tetangganya dibandingkan dengan cluster-nya saat ini. Tetapi pada kasus ini kita akan melanjutkan ke proses interpretasi cluster dan mengabaikan galat ini. Tentu akan lebih baik kalau kamu bisa menggunakan metode clustering lain untuk menghindari adanya pencilan/outlier seperti ini :D.
Sebelum kita bisa memvisualisasikan data yang sudah kita cluster, kita perlu menggabungkan data cluster yang sudah kita buat dari proses hierarchical clustering ke dalam dataset awal yang kita punya.
Tambahkan widget Data > Merge Data, kemudian pilih Append columns from Extra data dan pilih atribut provinsi pada bagian Row matching. Selain itu kamu juga bisa menambahkan widget Data Table untuk melihat data hasil clustering.
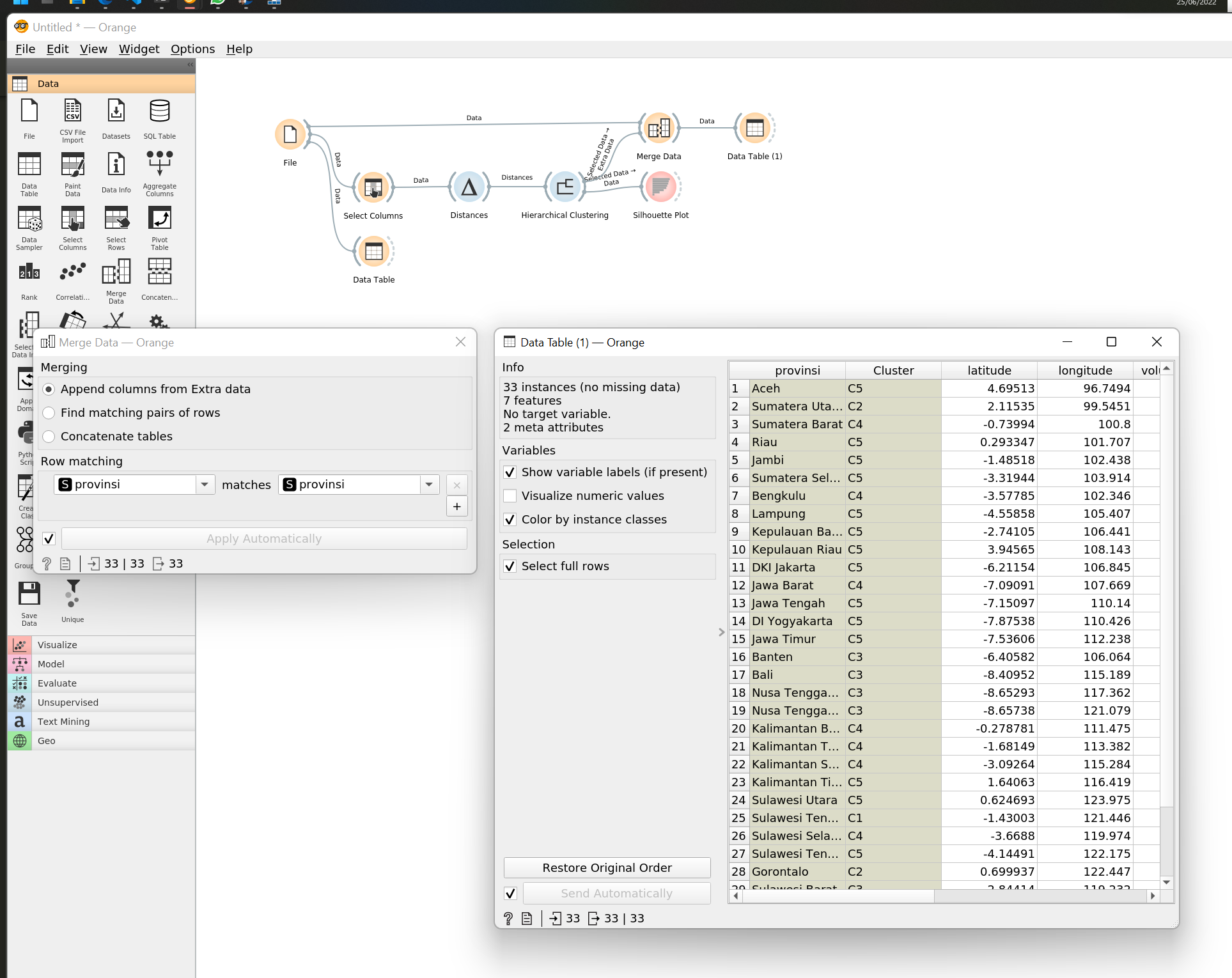
Workflow pada tutorial ini sedikit berbeda dengan workflow asli pada paper, tetapi output yang dihasilkan sama.
Pada gambar di atas dapat dilihat bahwa tiap-tiap baris data pada dataset awal sudah memiliki cluster hasil hierarchical cluustering. Untuk mempermudah proses interpretasi karakteristik tiap-tiap cluster, kita bisa menggunakan Box Plot.
Tambahkan widget Visualize > Box Plot, kemudian pilih variabel yang ingin kamu visualisasikan (misalnya
jumlah_hari_hujan) dan pilih Cluster sebagai Subgroups.
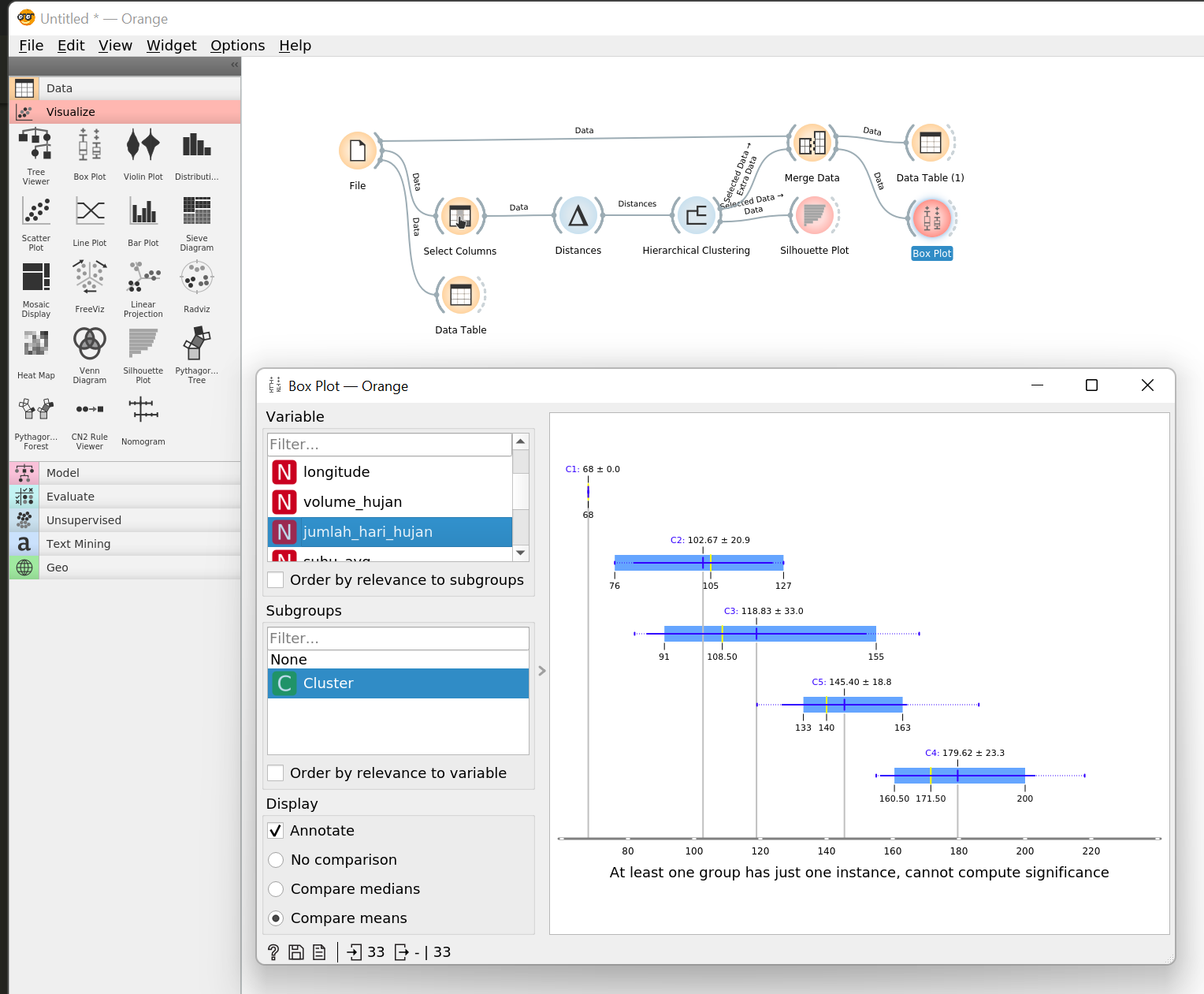
Box plot terdiri atas beberapa komponen, yaitu:
- Nilai paling ujung adalah Q1 (25%) dan Q3 (75%)
- Garis biru di tengah adalah mean atau Q2 (50%)
- Garis panjang merupakan median
Pada box plot di atas dapat dilihat bahwa C1 adalah cluster dengan curah hujan paling sedikit dalam satu tahun dan C4 adalah cluster dengan curah hujan paling banyak. Kamu bisa membuat box plot untuk variabel-variabel lain untuk mengambil lebih banyak insight untuk menentukan provinsi mana yang cocok untuk pertanian bawang putih.
Widget Box Plot dapat melakukan perbandingan antara mean dan median menggunakan ANOVA dan Chi-square Tetapi pada data ini karena terdapat satu cluster yang memiliki satu titik data saja, maka tidak dapat dilakukan analisis signifikansi antara dua mean
Tahap terakhir dari proses data mining pada penelitian ini adalah membuat visualisasi cluster pada peta untuk melihat secara visual clsuter dari tiap-tiap provinsi.
Pastikan Anda sudah memasang Add-on Orange-Geo untuk memvisualisasikan data pada peta
Tambahkan widget Geo > Geo Map, kemudian pilih atribut latitude dan longitude pada grup koordinat peta dan pilih
atribut Cluster pada kolom Color dan Shape. Untuk menampilkan daerah arsiran warna cluster, centang pada Show
color regions.
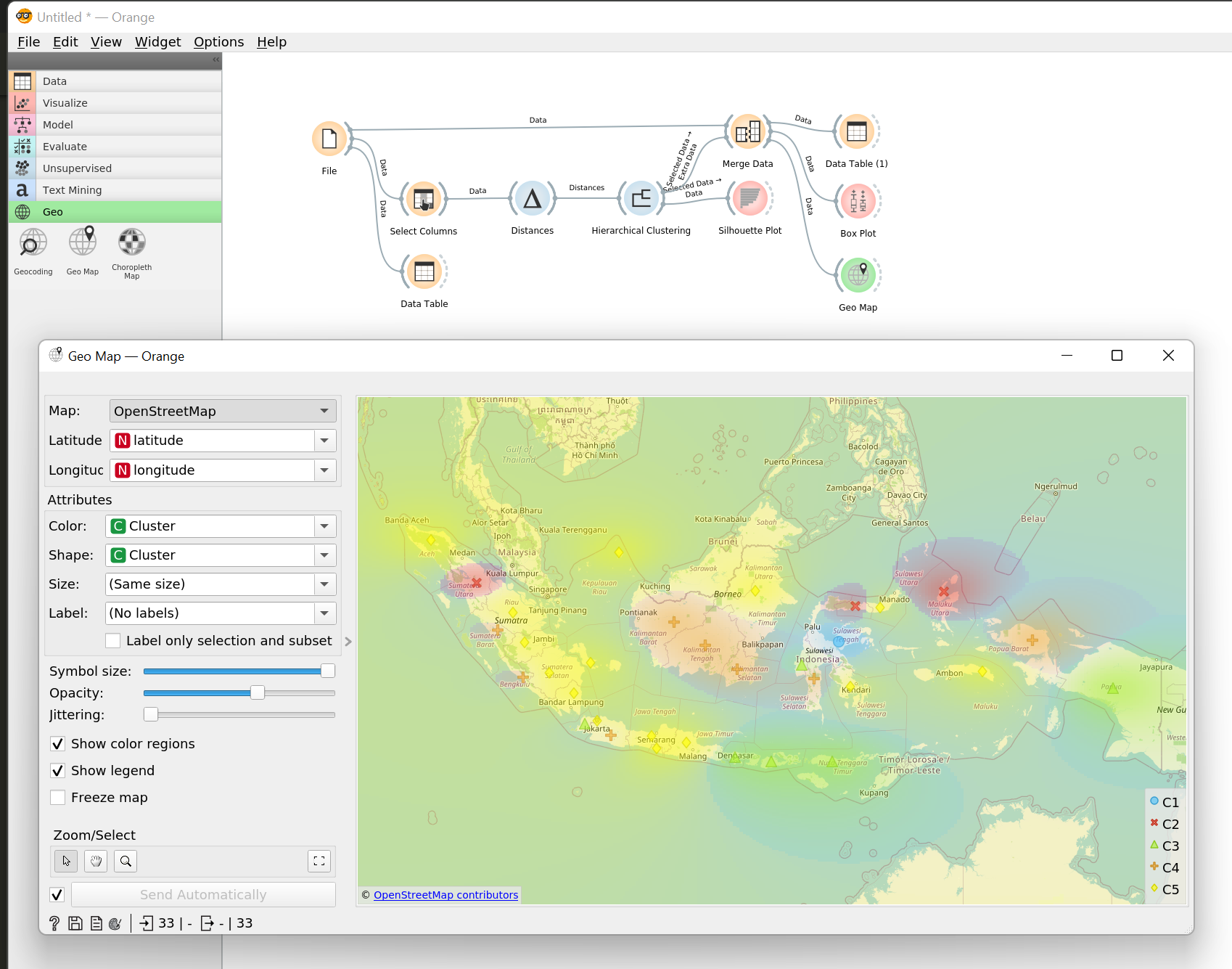
Dapat dilihat pada peta bahwa C1 yang merupakan provinsi yang paling kering terdapat di pulau Sulawesi dan secara umum cluster-cluster pulau tersebar merata yang menunjukkan adanya variasi yang tinggi pada kondisi cuaca di Indonesia yang dapat memengaruhi potensi pertanian bawang putih.
Simpulan
Dikutip dari paper,
- C1, memiliki curah hujan paling sedikit dan kondisi cuaca panas kering.
- C2, memiliki curah hujan yang sedikit dengan rata-rata 102 hari hujan, dengan penyinaran matahari yang bervariasi antara 51-84 hari dengan rata-rata suhu 27,3 °C.
- C3, memiliki curah hujan sedikit lebih banyak dibandingkan C2, dengan penyinaran matahari yang lebih lama antara 65-84 hari dengan rata-rata suhu 27,13 °C.
- C4, memiliki curah hujan paling banyak dengan rata-rata 145 hari hujan, memiliki penyinaran matahari yang paling sedikit, dan suhu yang paling dingin dibandingkan cluster lainnya.
- C5, memiliki curah hujan yang besar dengan rata-rata 145 hari hujan, memiliki penyinaran matahari antara 51,97 dan 72,51 hari, dengan suhu antara 27-27,9 °C.
Berdasarkan data tersebut, dapat disimpulkan bahwa cluster C3 merupakan kandidat terbaik sebagai lokasi budidaya bawang putih. Provinsi yang termasuk pada cluster C3 yaitu Banten, Bali, Nusa Tenggara Barat, Nusa Tenggara Timur, Sulawesi Barat, dan Papua.
Penutup
Pada artikel ini kita telah merekonstruksi paper untuk melakukan data mining menggunakan aplikasi Orange Data Mining dengan studi kasus untuk melakukan clustering untuk mengelompokkan provinsi-provinsi yang memiliki potensi sebagai daerah produsen bawang putih berdasarkan kondisi cuaca pada masing-masing provinsi.
Yuk kita coba pelajari bagaimana penggunaan Orange Data Mining untuk melakukan proses analisis lain dan bagi teman-teman yang lebih suka versi video, teman-teman bisa cek playlist YouTube penulis di mana penulis membahas beberapa studi kasus lain menggunakan aplikasi Orange Data Mining!
Terima kasih sudah membaca artikel kali ini, sampai jumpa nanti!